
Fuxiao Liu
刘赋骁
Research Scientist at NVIDIA, working on the Nemotron family of foundation models.
Ph.D. from University of Maryland, College Park (May 2025), advised by Abhinav Shrivastava, Yaser Yacoob, Tianyi Zhou, and Furong Huang.
My recent focus is on building customizable, efficient, and open multimodal foundation models.
Selected Publications
Nemotron 3
Nano Omni
Nano Omni
NVIDIA · 2026
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence NEWCore Author
NVIDIA
Nemotron
Nano 2 VL
Nemotron
Nano 2 VL
NVIDIA · 2025
NVIDIA Nemotron Nano V2 VL: Efficient Open Vision-Language Foundation Model NEWCore Author
Nemotron-H
Mamba ⨯ Transformer
Mamba ⨯ Transformer
NVIDIA · 2025
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba–Transformer Models NEWCore Author

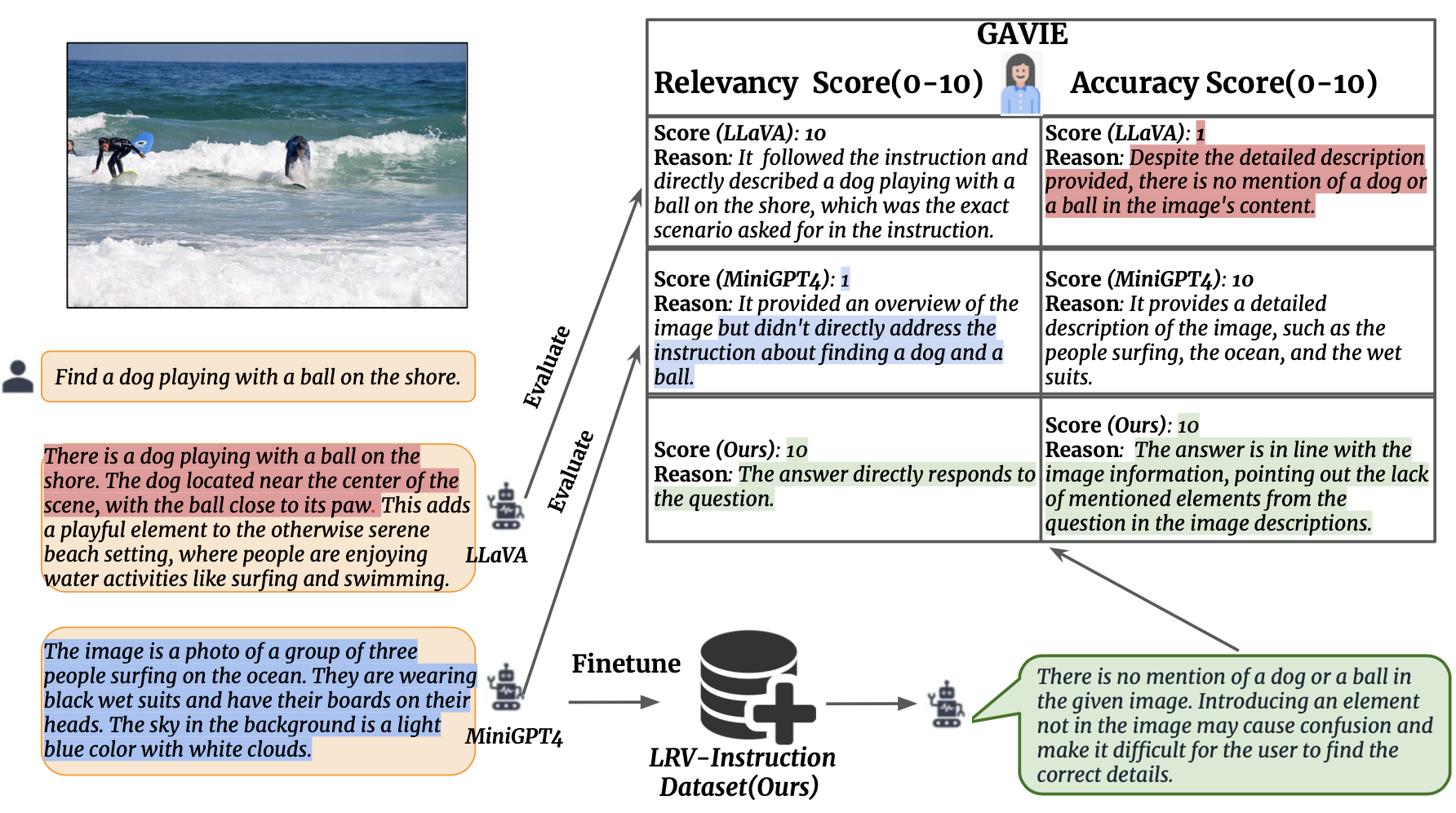

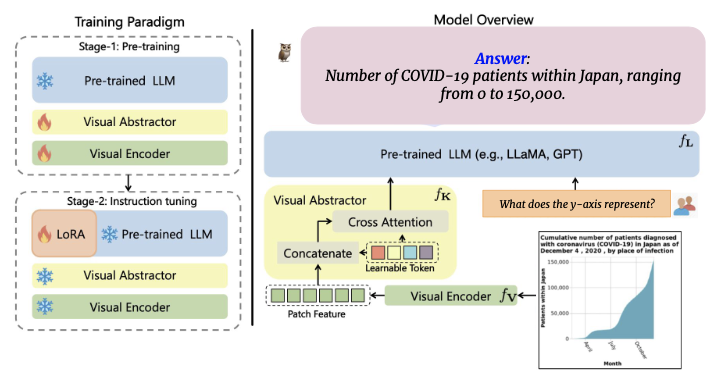
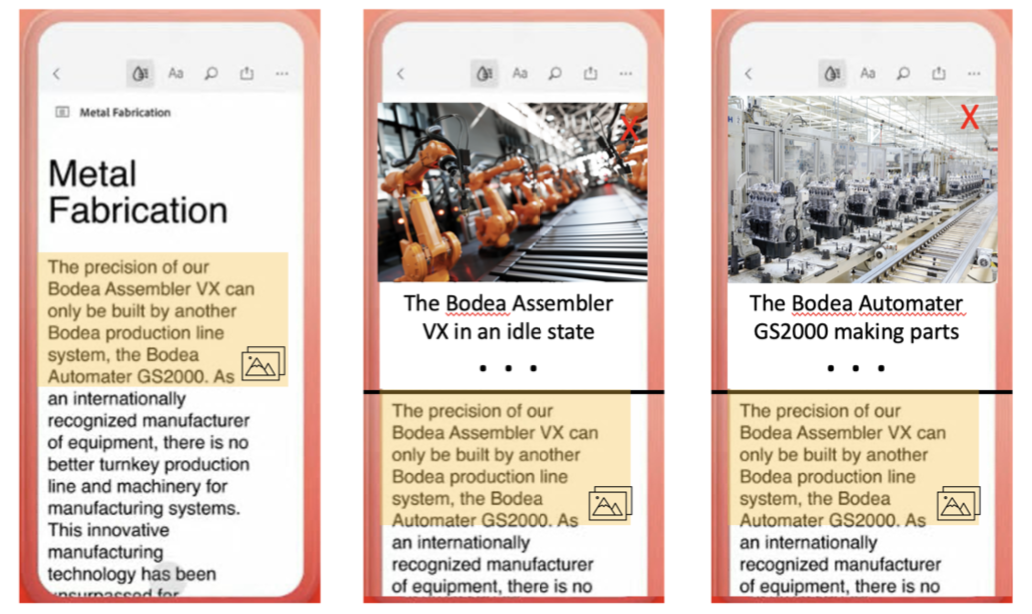
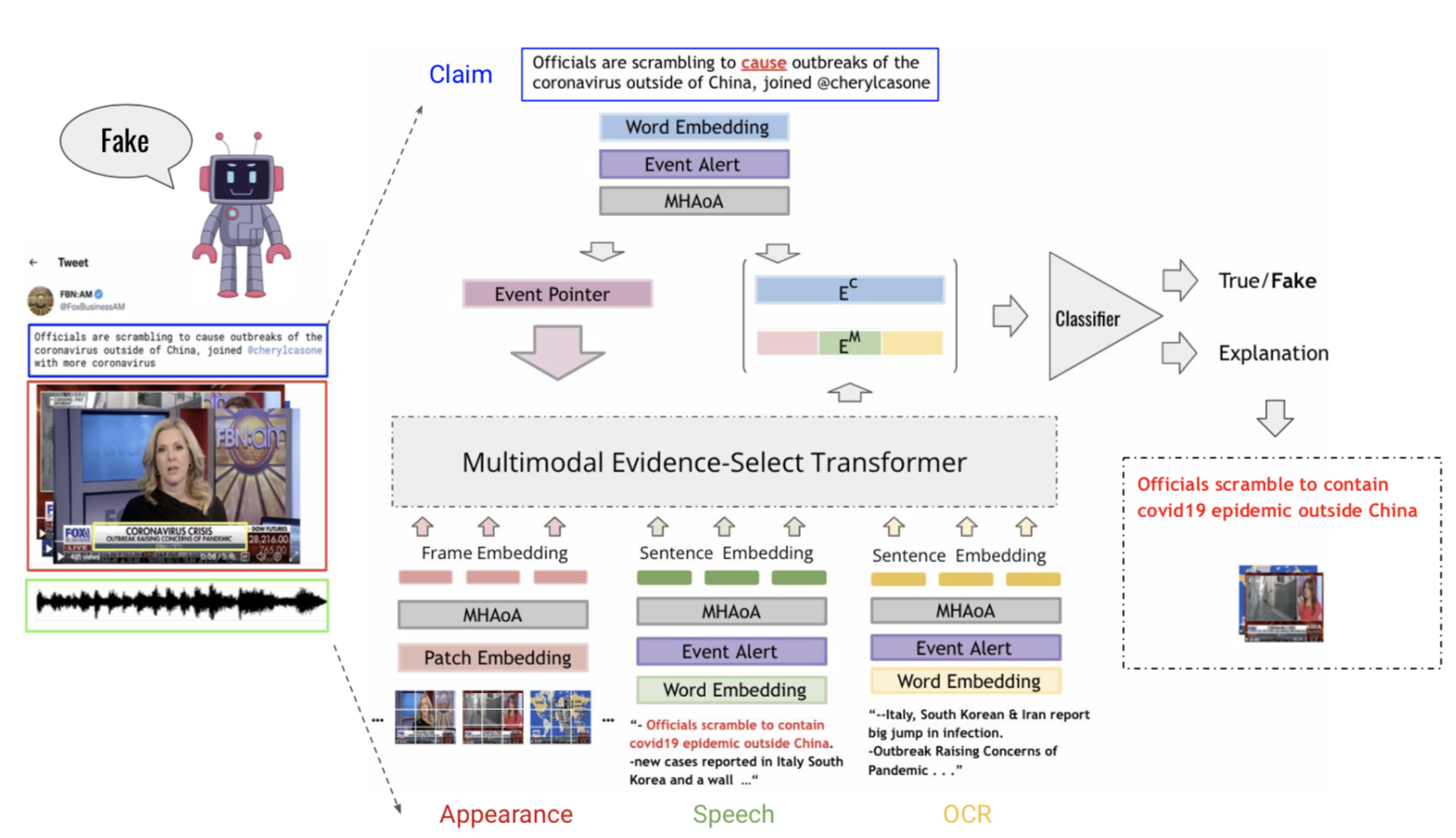

Other Publications
[NeurIPS 2024 Workshop]
Towards understanding in-context learning with contrastive demonstrations and saliency maps
[LREC-COLING 2024]
From Multimodal LLM to Human-level AI: Modality, Instruction, Reasoning, Efficiency and Beyond
Service
Conference Reviewer
AISTATS, CVPR, NAACL, ACL, IJCAI, ACMMMJournal Reviewer
JMIRAbout
I'm crazy about basketball since I was a little boy. I love it for its ultimate technical and mentality requirements.
No one in the world can become a master without great talent and extensive training.
My favorite basketball player is Kobe Bryant, who is noted for his rapid playing style, strong will, and his ambivalent relationship with the sport.
I am always immersed in his phenomenal performance in the game.